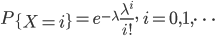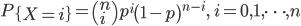首先证明Sherman-Morrison公式:
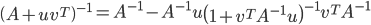
其中,
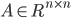 非奇异,即A-1存在,
非奇异,即A-1存在, ,
, 。SM公式看似复杂,但可以通过求解[......]
。SM公式看似复杂,但可以通过求解[......]
Random Walk in VAR
本文来源于网络,原英文作者是Tom Yeh,后来Liu Wei把原文翻译成中文,对隐式马尔可夫模型(HMM)进行了生动的描述。出处链接均已失效,故无法在本文提供最初的出处链接,谨对两位作者表示感谢。以下是Liu Wei的中文译文——
首先感谢原英文作者Tom Yeh在其主页的精彩描述,生动地讲述了HMM模型的原理,在此我斗胆用我自己的语言用中文修改描述一次。
男生和女生分别是来自不同星球的科学事实已经众所周知的了。男生们总是认为,女生们都是迷一样的生物,他们的情感状态浮动似乎是以秒单位在变化的,难以理解,更勿论预测了!而女生们觉得男生都是没有感觉动物,完全不能理解什么叫感受——尽管[......]
5月5日,美国国安局负责招聘的Twitter帐户发表了一条内容看似错乱无章的推特[1]:
tpfccdlfdtte pcaccplircdt dklpcfrp?qeiq lhpqlipqeodf gpwafopwprti izxndkiqpkii krirrifcapnc dxkdciqcafmd vkfpcadf. #MissionMonday #NSA #news
该推特很快就被破解了:
Want to know what it takes to work at NSA? Check back each Monday in May as we explore careers es[......]
在使用python最著名的画图库matplotlib画图时,若图表中有中文,默认会存在显示问题,如:
|
1 2 3 4 5 6 7 8 9 10 |
from pylab import * x = arange(-5*pi, 5*pi, 0.01) y = sin(x)/x plot(x, y) title('sin(x)/x曲线') xlabel('横轴') ylabel('幅度') grid(True) savefig("sinc函数.png") show() |
这是由于matplotlib的\Python33\Lib\site-packages\matplotlib\mpl-data\matplotlibrc文件中没有定义能正确显示中文的字体,解决方法是,在代码中添加一行指定使用的字体,如下面代码中的第二行指定使用微软雅黑字体:
|
1 2 3 4 5 6 7 8 9 10 11 |
from pylab import * mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] x = arange(-5*pi, 5*pi, 0.01) y = sin(x)/x plot(x, y) title('sin(x)/x曲线') xlabel('横轴') ylabel('幅度') grid(True) savefig("sinc函数.png") show() |
 [......]
[......]
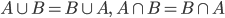
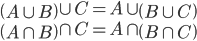
$$!\begin{array}{c} \left( A\cup B \right)\cap C=\left( A\cap C \right)\cup \left([......]
1859年到1872年,达尔文的《物种起源》进行了6次修订,Processing的创始人之一Ben Fry(另一位是Casey Reas)使用Processing对6个版本的修订内容进行了可视化分析:http://benfry.com/traces/,不同颜色代表不同版本之间的改动地方。

Processing是一种开源编程语言,专门为电子艺术和视觉交互设计而创建,其目的是通过可视化的方式辅助编程教学,并在此基础之上表达数字创意。Processing是Java语言的延伸,并支持许多现有的Java语言架构,不过在语法上简易许多。关于Processing的参考书籍,最权威的应该是该语言的两位创[......]
Tagxedo(http://www.tagxedo.com/app.html)是一款制作个性化词云的在线工具,它不仅支持英文,还完美支持中文,并且支持定义云的外形、颜色、字体、排列方向,能够导出jpg或png格式的词云图片进行分享。下图是将乔布斯在斯坦福大学毕业典礼上的演讲英文稿制作成苹果标志的词云。
 [......]
[......]
|
1 2 3 4 5 6 7 8 9 10 11 |
#-*- coding:utf-8 -*- from collections import Counter # 统计总汉字数,文本均以utf-8格式保存 TotalChar = [x for x in open("D:\Eric5\红楼梦.txt", "r", encoding="utf-8").read() if 19968<=ord(x)<=40869] # 统计不同汉字的重复次数 CountChar = Counter(TotalChar) print("总汉字数:", len((TotalChar))) print("不同汉字数:", len((CountChar))) print(CountChar) |
对我国四大名著的统计结果如下,并列出重复次数最多的前十个字:
《红楼梦》
总汉字数: 731598
不同汉字数: 4253
[('了', 21229), ('的', 15736), ('不', 15038), ('一', 12194), ('来', 11450), ('道', 11061), ('人', 10558), ('是', 10151), ('说', 9710), ('我', 9176)]
《西游记》
总汉字数: 584058
不同汉字数: 4458
[('道', 10994), ('不',[......]